

Extracción Semántica de Conjunto Abierto: Pipeline de Grounded-SAM, CLIP y DINOv2
Tabla de enlaces
Abstracto y 1 Introducción
-
Trabajos relacionados
2.1. Navegación de visión y lenguaje
2.2. Comprensión semántica de escenas y segmentación de instancias
2.3. Reconstrucción de escenas 3D
-
Metodología
3.1. Recopilación de datos
3.2. Información semántica de conjunto abierto a partir de imágenes
3.3. Creación de la representación 3D de conjunto abierto
3.4. Navegación guiada por lenguaje
-
Experimentos
4.1. Evaluación cuantitativa
4.2. Resultados cualitativos
-
Conclusión y trabajo futuro, declaración de divulgación y referencias
3.2. Información semántica de conjunto abierto a partir de imágenes
\ 3.2.1. Detección de máscaras semánticas y de instancias de conjunto abierto
\ El modelo Segment Anything (SAM) [21] recientemente lanzado ha ganado una popularidad significativa entre investigadores y profesionales industriales debido a sus capacidades de segmentación de vanguardia. Sin embargo, SAM tiende a producir un número excesivo de máscaras de segmentación para el mismo objeto. Adoptamos el modelo Grounded-SAM [32] para nuestra metodología para abordar esto. Este proceso implica generar un conjunto de máscaras en tres etapas, como se muestra en la Figura 2. Inicialmente, se crea un conjunto de etiquetas de texto utilizando el modelo Recognizing Anything (RAM) [33]. Posteriormente, se crean cuadros delimitadores correspondientes a estas etiquetas utilizando el modelo Grounding DINO [25]. La imagen y los cuadros delimitadores se introducen luego en SAM para generar máscaras de segmentación agnósticas de clase para los objetos vistos en la imagen. Proporcionamos una explicación detallada de este enfoque a continuación, que mitiga eficazmente el problema de la sobresegmentación al incorporar conocimientos semánticos de RAM y Grounding-DINO.
\ El modelo RAM [33] procesa la imagen RGB de entrada para producir el etiquetado semántico del objeto detectado en la imagen. Es un modelo fundacional robusto para el etiquetado de imágenes, mostrando una notable capacidad de zero-shot para identificar con precisión varias categorías comunes. La salida de este modelo asocia cada imagen de entrada con un conjunto de etiquetas que describen las categorías de objetos en la imagen. El proceso comienza con el acceso a la imagen de entrada y su conversión al espacio de color RGB, luego se redimensiona para adaptarse a los requisitos de entrada del modelo, y finalmente se transforma en un tensor, haciéndolo compatible con el análisis del modelo. Después de esto, el modelo RAM genera etiquetas, o tags, que describen los diversos objetos o características presentes dentro de la imagen. Se emplea un proceso de filtración para refinar las etiquetas generadas, que implica la eliminación de clases no deseadas de estas etiquetas. Específicamente, se descartan etiquetas irrelevantes como "pared", "suelo", "techo" y "oficina", junto con otras clases predefinidas consideradas innecesarias para el contexto del estudio. Además, esta etapa permite la ampliación del conjunto de etiquetas con cualquier clase requerida no detectada inicialmente por el modelo RAM. Finalmente, toda la información pertinente se agrega en un formato estructurado. Específicamente, cada imagen se cataloga dentro del diccionario img_dict, que registra la ruta de la imagen junto con el conjunto de etiquetas generadas, asegurando así un repositorio accesible de datos para análisis posteriores.
\ Después del etiquetado de la imagen de entrada con etiquetas generadas, el flujo de trabajo progresa invocando el modelo Grounding DINO [25]. Este modelo se especializa en conectar frases textuales a regiones específicas dentro de una imagen, delineando efectivamente objetos objetivo con cuadros delimitadores. Este proceso identifica y localiza espacialmente objetos dentro de la imagen, sentando las bases para análisis más granulares. Después de identificar y localizar objetos mediante cuadros delimitadores, se emplea el modelo Segment Anything (SAM) [21]. La función principal del modelo SAM es generar máscaras de segmentación para los objetos dentro de estos cuadros delimitadores. Al hacerlo, SAM aísla objetos individuales, permitiendo un análisis más detallado y específico del objeto al separar efectivamente los objetos de su fondo y entre sí dentro de la imagen.
\ En este punto, las instancias de objetos han sido identificadas, localizadas y aisladas. Cada objeto se identifica con varios detalles, incluidas las coordenadas del cuadro delimitador, un término descriptivo para el objeto, la probabilidad o puntuación de confianza de la existencia del objeto expresada en logits, y la máscara de segmentación. Además, cada objeto está asociado con características de incrustación CLIP y DINOv2, cuyos detalles se elaboran en la siguiente subsección.
\ 3.2.2. La extracción de incrustación semántica
\ Para mejorar nuestra comprensión de los aspectos semánticos de las instancias de objetos que han sido segmentados y enmascarados dentro de nuestras imágenes, empleamos dos modelos, CLIP [9] y DINOv2 [10], para derivar las representaciones de características de las imágenes recortadas de cada objeto. Un modelo entrenado exclusivamente con CLIP logra una comprensión semántica robusta de las imágenes, pero no puede discernir la profundidad y los detalles intrincados dentro de esas imágenes. Por otro lado, DINOv2 demuestra un rendimiento superior en la percepción de profundidad y sobresale en la identificación de relaciones matizadas a nivel de píxel entre imágenes. Como un Vision Transformer autocontrolado, DINOv2 puede extraer detalles de características matizados sin depender de datos anotados, lo que lo hace particularmente efectivo para identificar relaciones espaciales y jerarquías dentro de las imágenes. Por ejemplo, mientras que el modelo CLIP podría tener dificultades para diferenciar entre dos sillas de diferentes colores, como rojo y verde, las capacidades de DINOv2 permiten que tales distinciones se hagan claramente. Para concluir, estos modelos capturan tanto las características semánticas como visuales de los objetos, que luego se utilizan para comparaciones de similitud en el espacio 3D.
\ 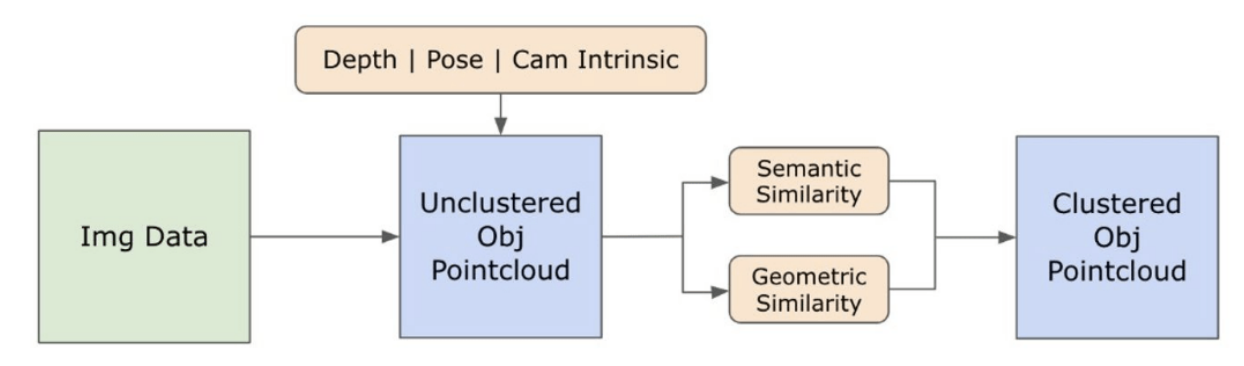
\ Se implementa un conjunto de pasos de preprocesamiento para procesar imágenes con el modelo DINOv2. Estos incluyen redimensionar, recortar el centro, convertir la imagen a un tensor y normalizar las imágenes recortadas delineadas por los cuadros delimitadores. La imagen procesada se introduce luego en el modelo DINOv2 junto con las etiquetas identificadas por el modelo RAM para generar las características de incrustación DINOv2. Por otro lado, al tratar con el modelo CLIP, el paso de preprocesamiento implica transformar la imagen recortada en un formato de tensor compatible con CLIP, seguido del cálculo de características de incrustación. Estas incrustaciones son críticas ya que encapsulan los atributos visuales y semánticos de los objetos, que son cruciales para una comprensión integral de los objetos en la escena. Estas incrustaciones se someten a normalización basada en su norma L2, que ajusta el vector de características a una longitud unitaria estandarizada. Este paso de normalización permite comparaciones consistentes y justas entre diferentes imágenes.
\ En la fase de implementación de esta etapa, iteramos sobre cada imagen dentro de nuestros datos y ejecutamos los procedimientos subsiguientes:
\ (1) La imagen se recorta a la región de interés utilizando las coordenadas del cuadro delimitador proporcionadas por el modelo Grounding DINO, aislando el objeto para un análisis detallado.
\ (2) Generar incrustaciones DINOv2 y CLIP para la imagen recortada.
\ (3) Finalmente, las incrustaciones se almacenan junto con las máscaras de la sección anterior.
\ Con estos pasos completados, ahora poseemos representaciones de características detalladas para cada objeto, enriqueciendo nuestro conjunto de datos para análisis y aplicación adicionales.
\
:::info Autores:
(1) Laksh Nanwani, Instituto Internacional de Tecnología de la Información, Hyderabad, India; este autor contribuyó igualmente a este trabajo;
(2) Kumaraditya Gupta, Instituto Internacional de Tecnología de la Información, Hyderabad, India;
(3) Aditya Mathur, Instituto Internacional de Tecnología de la Información, Hyderabad, India; este autor contribuyó igualmente a este trabajo;
(4) Swayam Agrawal, Instituto Internacional de Tecnología de la Información, Hyderabad, India;
(5) A.H. Abdul Hafez, Universidad Hasan Kalyoncu, Sahinbey, Gaziantep, Turquía;
(6) K. Madhava Krishna, Instituto Internacional de Tecnología de la Información, Hyderabad, India.
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC by-SA 4.0 Deed (Atribución-Compartir igual 4.0 Internacional).
:::
\
También te puede interesar

Cambio de SOL a Ozak AI: Por qué algunos inversores creen que el token de IA tiene mayor potencial a largo plazo

¡Debby Ryan y Josh Dun, de Twenty One Pilots, ya son papás! Así anunciaron el nacimiento de su bebé
