

غلبه بر تکهتکه شدن دادهها و محدودیتهای هوش مصنوعی در سودآوری معاملات
در یک نشست اختصاصی از FF News Virtual Arena، متخصصان صنعت گرد هم آمدند تا درباره یک گلوگاه حیاتی در عملیات بانکی بحث کنند: اینکه چگونه تکهتکه شدن دادهها و معماری قدیمی مستقیماً باعث میشوند مؤسسات مالی در جریانهای معاملاتی خود سودآوری را از دست بدهند.
شرکتکنندگان در این بحث:
-
Ian Horne، مجری FF News
-
Mariia Komissarova، مسئول کسبوکار خردهفروشی داده و هوش مصنوعی در Raiffeisen Bank International
-
Breno Alves De Oliveira، مدیر ارشد محصول در PAYABL
-
Kirill Lisitsyn، همبنیانگذار و مدیرعامل Torus
این پانل هزینههای عملیاتی پنهان مجموعههای دادهای بلااستفاده، محدودیتهای هوش مصنوعی غیرقطعی، و استراتژیهایی را که مؤسسات مالی باید برای تبدیل دادههای خام به پایهای اصلی برای بقای بازار به کار گیرند، بررسی کرد.
ریشه نشت سود: موانع زیرساخت قدیمی و دادههای ساختاریافته
برای مؤسسات مالی چندنسلی در بازار، مانند Raiffeisen Bank International، زیرساخت قدیمی به عنوان یک مانع داخلی اصلی برای بهینهسازی برجسته است. Mariia Komissarova توضیح داد که چالش اصلی که باعث میشود بانکها در جریانهای معاملاتی سودآوری را از دست بدهند، در اصل یک مشکل داده است.
از آنجا که برنامههای کاربردی بانکی تاریخی در سیلوهای مجزا فعالیت میکنند، جمعآوری و ساختاردهی به دادههای معاملاتی شرکتی در قالبی شفاف و سازمانیافته بهشدت دشوار است. بدون یک چارچوب ساختاریافته، محاسبه سودآوری دقیق یک معامله مالی فردی عملاً غیرممکن میماند.
این شکست از حاکمیت دادههای تاریخی و فقدان استقرار چارچوبهای مدرن ناشی میشود. الگوهای سازمانی پیشرفته، مانند مفهوم "data mesh"، در بازار ظهور کردهاند اما در سراسر بنگاههای بزرگ بانکی بهخوبی توزیع نشدهاند.
با توجه به اینکه بخش مالی جهانی در حال گذار از تحولات گسترده هوش مصنوعی در احراز هویت و پردازش معاملات است، رفع این لایه دادهای دیگر یک امتیاز نیست. ایجاد یک پایه دادهای پاکیزه به یک الزام مطلق برای بقای بلندمدت شرکتها تبدیل شده است.
شبکه هزینههای پنهان جذب انبوه داده
یک دام رایج برای مؤسسات قدیمی این فرض است که جمعآوری حجم بیشتر داده بهطور طبیعی ارزش تجاری بیشتری ایجاد میکند. پنج تا هفت سال پیش، راهنماهای صنعتی سنتی بر جمعآوری هر چه بیشتر نقاط داده متنوع تمرکز داشتند، از جمله انتقال داده از شبکههای رسانههای اجتماعی به سرورهای شرکتی.
اکوسیستم معاملاتی مدرن از این طرز فکر فراتر رفته است. مؤسسات مالی دریافتهاند که صرفاً ذخیرهسازی و نگهداری حجم عظیمی از اطلاعات بدون ساختار، هزینههای سنگین سرور و مهندسی داده به همراه دارد.
"این مقدار داده، حجم زیادی از داده برای جمعآوری و ذخیرهسازی آنها، بسیار پرهزینه است و اگر از آن استفاده نکنید، در این بازی قیمتگذاری نیز شروع به عقب افتادن میکنید..."
وقتی یک شرکت هزینههای سنگین ذخیرهسازی عملیاتی را متحمل میشود بدون اینکه ارزش تجاری از آن دادهها استخراج کند، در بازی رقابتی قیمتگذاری عقب میماند. نمیتواند نرخهای بهینه به پذیرندگان خود ارائه دهد زیرا هزینههای پایه زیرساخت آن بهطور مصنوعی افزایش یافته است.
همانطور که Kirill Lisitsyn تأکید کرد، استراتژی داده مدرن باید در وهله اول بر استخراج ارزش واقعی از داراییهای داده موجود تمرکز کند. تنها زمانی که یک مورد استفاده تجاری صریح تعریف شده باشد، یک مؤسسه باید سرمایهگذاری کند تا جریانهای داده اضافی به دست آورد و از این طریق از موانع عملیاتی غیرضروری و انباشت هزینه جلوگیری کند.
دام غیرقطعی: چرا LLMها نمیتوانند دادههای بد را اصلاح کنند
در حالی که مؤسسات برای یکپارچهسازی سیستمهای قدیمی که به زبانهای نرمافزاری کاملاً متفاوت صحبت میکنند و از فرمتهای داده غیراستاندارد استفاده میکنند تلاش میکنند، بسیاری به هوش مصنوعی و مدلهای زبانی بزرگ (LLMs) روی میآورند تا تبدیل کد و داده را خودکار کنند. Breno Alves De Oliveira اشاره کرد که فینتکها در جذب دادههای پیچیده و سازماندهی مجدد آنها در قالبهای قابل هضم برتری دارند، فرآیندی که بهشدت توسط ابزارهای هوش مصنوعی شتاب گرفته است.
با این حال، Komissarova یک هشدار فنی جدی درباره اتکای بیش از حد به الگوریتمهای مولد برای زیرساخت معاملاتی اصلی صادر کرد. LLMها ذاتاً غیرقطعی هستند، به این معنا که خروجیهای آنها مبتنی بر احتمال هستند نه مطلق، که آنها را در معرض خطر سیستماتیک توهمات الگوریتمی قرار میدهد.
در دنیای معاملاتی، جایی که خطاها مستقیماً بر دفاتر مالی تأثیر میگذارند، افت از دقت کامل غیرقابل قبول است. وارد کردن دادههای نادرست یا بدون ساختار به یک LLM بهطور قابل توجهی احتمال تولید محاسبات نادرست را افزایش میدهد و بهطور بالقوه میتواند میلیونها دلار به مؤسسات مالی آسیب برساند.
پانل توافق کرد که هیچ راهحل فناورانه جادویی وجود ندارد؛ شرکتها نمیتوانند صرفاً مجموعه دادههای نامنظم را به یک مدل مولد بدهند و انتظار منطق تجاری بینقص داشته باشند. ساخت یک لایه داده قابل اعتماد نیازمند سرمایهگذاری منضبط زمان و سرمایه، همراه با متخصصان داخلی ماهری است که بتوانند خط لوله داده را بهدرستی ساختاردهی کنند.
برقراری تعادل: هسته ترکیبی قطعی
برای بهرهگیری ایمن از سرعت هوش مصنوعی مدرن بدون فدا کردن دقت مطلق مالی، شرکتکنندگان در پانل یک معماری ساختاری ترکیبی پیشنهاد دادند. این مدل موتورهای پردازش قطعی را با رابطهای زبانی انعطافپذیر برای تسهیل جریان کار کاربر نهایی متعادل میکند:
-
پایه قطعی: لایه داده اصلی باید کاملاً قطعی باقی بماند. پلتفرمهای هوشمند تخصصی، مانند Torus، عمداً منطق باطنی خود را برای تمرکز بر دقت ریاضی کامل به جای مدل "احتمال ۸۰٪" میسازند و اطمینان میدهند که کارمزدهای طرح و سوابق معاملاتی بهطور کامل تطبیق داده شوند.
-
رابط مکالمهای: پس از ایجاد یک خط پایه از یکپارچگی داده تأیید شده، مؤسسات میتوانند LLMها را روی آن لایهبندی کنند تا داده را تفسیر کنند، تعاملات کاربر را سادهتر کنند و وظایف تحلیلی را شتاب دهند.
این پایه ساختاریافته به مؤسسات اجازه میدهد از مفاهیمی مانند data lake برای تدوین و آزمایش فرضیههای تجاری استفاده کنند. در گذشته، کشف یک روند پردازشی یا ارزیابی یک متغیر قیمتگذاری نیازمند جستوجوهای دستی عظیم در پایگاه داده بود.
با یک هسته ترکیبی یکپارچه، تیمهای محصول میتوانند به سرعت فرضیهها را برای ارزیابی احتمال موفقیت آنها آزمایش کنند. در نهایت، این چارچوب به بانکها امکان میدهد آمار داخلی، چشمانداز رقبا و تغییرات کلان بازار را بهطور همزمان تحلیل کنند. این رویکرد مبتنی بر داده، تعدیلهای هدفمند در جریانهای تبدیل، مسیریابی معاملاتی و تجربیات محصول را هدایت میکند و سرمایهگذاریهای لازم را به محرکهای قابل پیشبینی سودآوری شرکتی تبدیل میکند.
نکات کلیدی از پانل Virtual Arena:
-
گلوگاه ساختار داده: جمعآوری داده در سیستمهای قدیمی که از فرمتهای مختلف استفاده میکنند، ردیابی دقیق سودآوری معاملاتی را بسیار پیچیده میکند.
-
هزینه بالای رکود داده: ذخیرهسازی حجم انبوه داده بدون موارد استفاده مشخص، هزینههای عملیاتی را افزایش میدهد و رقابتپذیری بانکها را در قیمتگذاری برای پذیرندگان کاهش میدهد.
-
ارزش در برابر حجم: هوش داده مدرن استخراج حداکثر سودمندی از داراییهای موجود را قبل از خرید جریانهای داده خارجی در اولویت قرار میدهد.
-
خطر هوش مصنوعی غیرقطعی: از آنجا که مدلهای هوش مصنوعی مولد مبتنی بر احتمال هستند، استفاده از آنها بر دادههای اصلی بدون ساختار خطر خطاهای محاسبه مالی را به همراه دارد.
-
طرح سیستم ترکیبی: معماریهای موفق یک لایه داده قطعی با دقت ۱۰۰٪ را با ابزارهای LLM مکالمهای روی آن برای تفسیر کاربر ترکیب میکنند.
-
نوآوری مبتنی بر فرضیه: بازطراحی چارچوبهای داده اصلی به تیمها اجازه میدهد تغییرات پردازشی را به سرعت اعتبارسنجی کنند و ریسک سرمایهگذاریهای سرمایهای را کاهش دهند.
این مطلب با عنوان غلبه بر تکهتکه شدن دادهها و محدودیتهای هوش مصنوعی در سودآوری معاملاتی برای اولین بار در FF News | Fintech Finance منتشر شد.


محتوای پیشنهادی
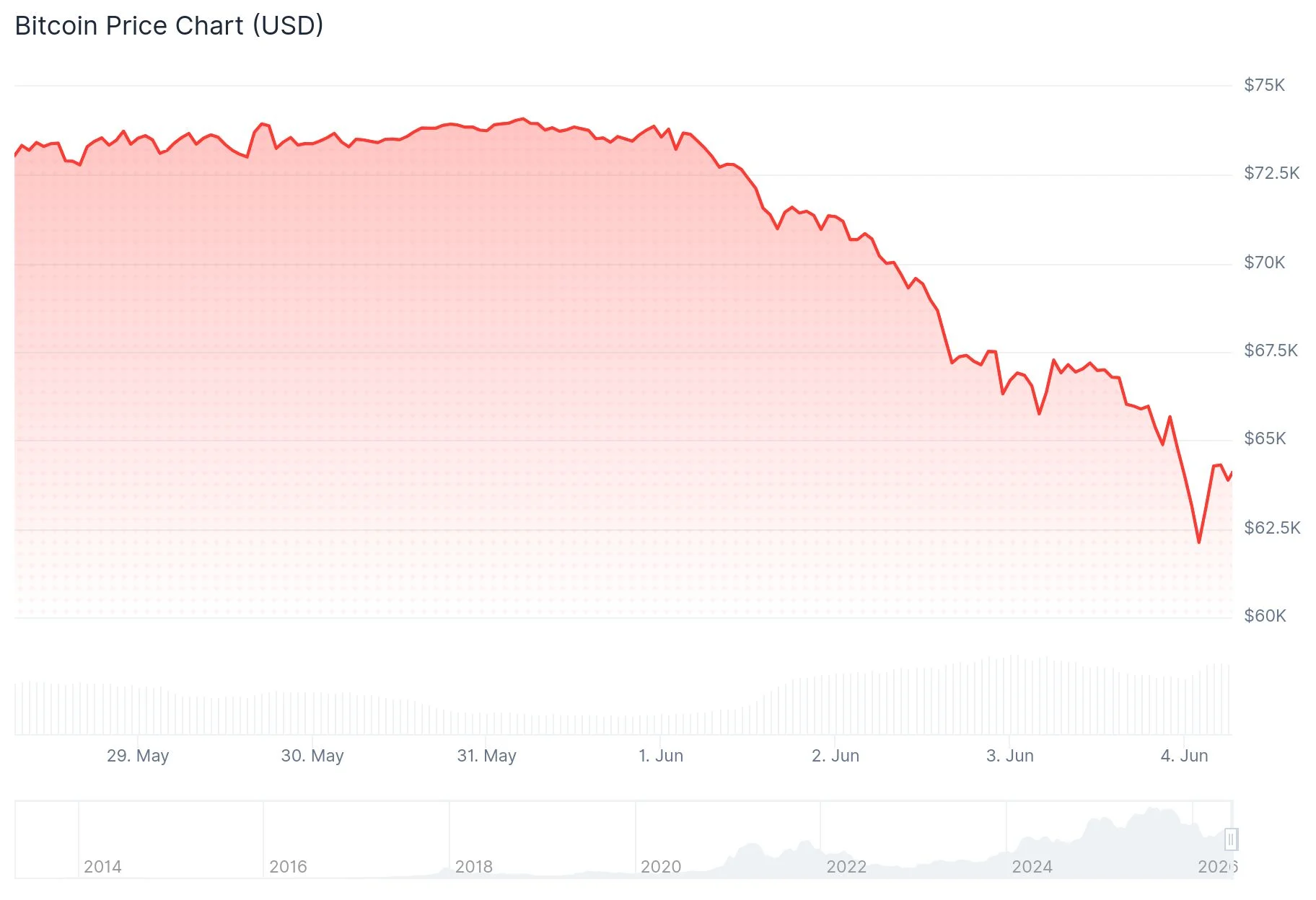
بیت کوین (BTC) در میان بزرگترین خروج سرمایه از ETF و موج ۱.۵ میلیارد دلاری لیکوئیدیشن به زیر ۶۲ هزار دلار سقوط کرد

صرافی فرانسوی Lise به دنبال IPO زنجیرهای برای گروه ST
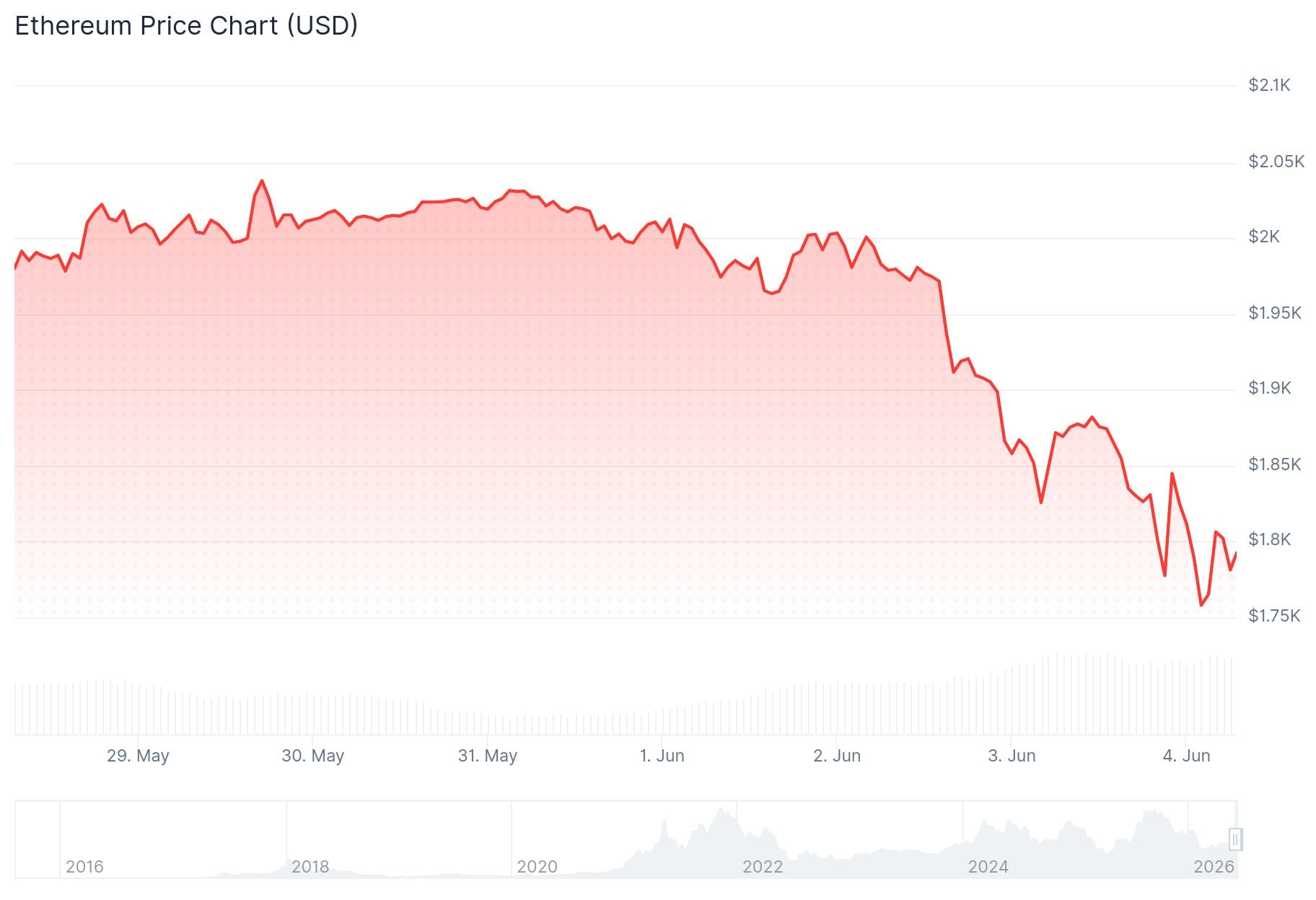
قیمت اتریوم (ETH): ETH به ۱۸۰۰ دلار رسید — تحلیلگران میگویند این آخرین توقف قبل از یک سقوط بسیار بزرگتر است



