

ELK, Loki et Graylog étaient excessifs, alors j'ai créé Log Bull
Depuis environ cinq ans, je suis confronté à la tâche de collecter des logs, généralement à partir de bases de code de petite à moyenne taille. Envoyer des logs depuis le code n'est pas un problème : Java et Go disposent de bibliothèques pour cela pratiquement prêtes à l'emploi. Mais déployer quelque chose pour les collecter est un casse-tête. Je comprends que c'est une tâche soluble (même avant ChatGPT, et maintenant encore plus). Pourtant, tous les systèmes de journalisation sont principalement orientés vers le monde des grandes entreprises et leurs exigences, plutôt que vers les petites équipes ou les développeurs individuels avec quelques bâtons, de la colle et une date limite "hier".
Lancer ELK est un défi pour moi à chaque fois : un tas de paramètres, un déploiement non trivial, et quand j'entre dans l'interface utilisateur, mes yeux s'affolent devant les onglets. Avec Loki et Graylog, c'est un peu plus facile, mais il y a toujours beaucoup plus de fonctionnalités que ce dont j'ai besoin. En même temps, séparer les logs entre les projets et ajouter d'autres utilisateurs au système pour qu'ils ne voient pas ce qu'ils ne devraient pas voir n'est pas non plus le processus le plus évident.
Il y a donc environ un an, j'ai décidé de créer mon propre système de collecte de logs. Un système aussi facile à utiliser et à lancer que possible. Il serait déployé sur le serveur avec une seule commande, sans aucune configuration ni onglets inutiles dans l'interface. C'est ainsi qu'est né Log Bull, et il est maintenant open source : un système de collecte de logs pour les développeurs avec des projets de taille moyenne.
Table des matières :
- À propos du projet
- Comment déployer Log Bull ?
- Comment envoyer des logs ?
- Comment consulter les logs ?
- Conclusion
À propos du projet
Log Bull est un système de collecte de logs qui met l'accent sur la facilité d'utilisation (configuration minimale, fonctionnalités minimales, zéro configuration au démarrage). Le projet est entièrement open source sous licence Apache 2.0. Ma priorité principale était de créer une solution qui permettrait à un développeur junior de comprendre facilement comment démarrer le système, comment lui envoyer des logs et comment les consulter en environ 15 minutes.

Caractéristiques principales du projet :
- Déployé avec une seule commande via un script .sh ou une commande Docker.
- Vous pouvez créer plusieurs projets isolés pour collecter des logs (et y ajouter des utilisateurs).
- Interface extrêmement simple avec une configuration minimale, et aucune configuration requise au démarrage (zéro configuration).
- Bibliothèques pour Python, Java, Go, JavaScript (TS \ NodeJS), PHP, C#. Rust et Ruby sont prévus.
- Gratuit, open source et auto-hébergé.
- Pas besoin de connaître LogQL, Kibana DSL ou d'autres langages de requête pour rechercher des logs.
https://www.youtube.com/watch?v=8H8jF8nVzJE&embedable=true
Le projet est développé en Go et construit sur OpenSearch.
Site web du projet - https://logbull.com
GitHub du projet - https://github.com/logbull/logbull
P.S. Si vous trouvez le projet utile et que vous avez un compte GitHub, veuillez lui donner une étoile ⭐️. Les premières étoiles sont difficiles à collecter. Je serais extrêmement reconnaissant pour votre soutien !
Comment déployer Log Bull ?
Il existe trois façons de déployer un projet : via un script .sh (que je recommande), via Docker et via Docker Compose.
Méthode 1 : Installation via script
Le script installera Docker, placera le projet dans le dossier /opt/logbull et configurera le démarrage automatique lors du redémarrage du système. Commande d'installation :
sudo apt-get install -y curl && \ sudo curl -sSL https://raw.githubusercontent.com/logbull/logbull/main/install-logbull.sh \ | sudo bash Méthode 2 : Lancement via Docker Compose
Créez le fichier docker-compose.yml avec le contenu suivant :
services: logbull: container_name: logbull image: logbull/logbull:latest ports: - "4005:4005" volumes: - ./logbull-data:/logbull-data restart: unless-stopped healthcheck: test: ["CMD", "curl", "-f", "http://localhost:4005/api/v1/system/health"] interval: 5s timeout: 5s retries: 30 Et exécutez la commande docker compose up -d. Le système démarrera sur le port 4005.
Méthode 3 : Lancement via commande Docker
Exécutez la commande suivante dans le terminal (le système démarrera également sur le port 4005) :
docker run -d \ --name logbull \ -p 4005:4005 \ -v ./logbull-data:/logbull-data \ --restart unless-stopped \ --health-cmd="curl -f http://localhost:4005/api/v1/system/health || exit 1" \ --health-interval=5s \ --health-retries=30 \ logbull/logbull:latest Comment envoyer des logs ?
J'ai conçu le projet en pensant à la commodité, principalement pour les développeurs. C'est pourquoi j'ai créé des bibliothèques pour la plupart des langages de développement populaires. Je l'ai fait avec l'idée que Log Bull peut être connecté à n'importe quelle bibliothèque populaire en tant que processeur sans modifier la base de code actuelle.
Je vous recommande vivement de consulter les exemples sur le site web, car il y a un panneau interactif pour sélectionner un langage :
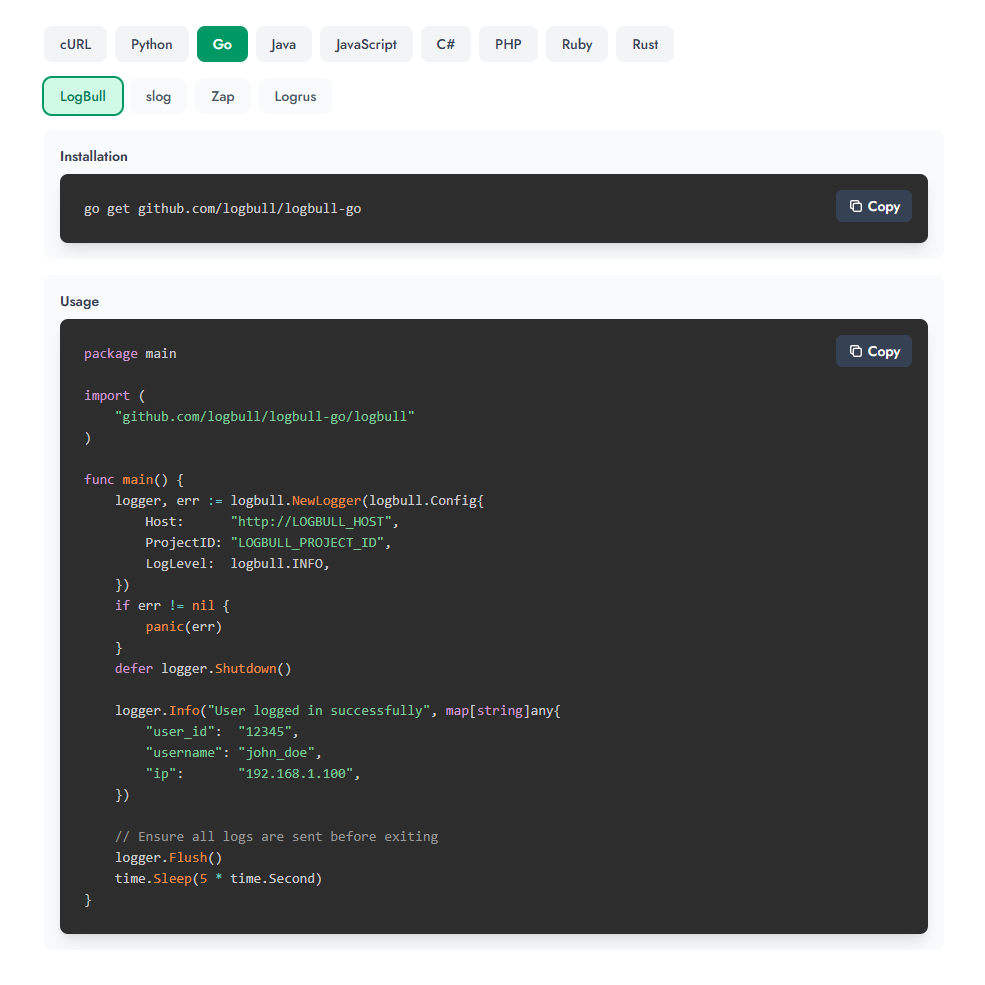
Prenons Python comme exemple. Tout d'abord, vous devez installer la bibliothèque (bien que vous puissiez également l'envoyer via HTTP ; il y a des exemples pour cURL) :
pip install logbull Puis envoyez depuis le code :
import time from logbull import LogBullLogger # Initialize logger logger = LogBullLogger( host="http://LOGBULL_HOST", project_id="LOGBULL_PROJECT_ID", ) # Log messages (printed to console AND sent to LogBull) logger.info("User logged in successfully", fields={ "user_id": "12345", "username": "john_doe", "ip": "192.168.1.100" }) # With context session_logger = logger.with_context({ "session_id": "sess_abc123", "user_id": "user_456" }) session_logger.info("Processing request", fields={ "action": "purchase" }) # Ensure all logs are sent before exiting logger.flush() time.sleep(5) Comment consulter les logs ?
Tous les logs sont affichés immédiatement sur l'écran principal. Vous pouvez :
-
Réduire la taille des messages (en coupant la ligne à ~50-100 caractères).
-
Développer la liste des champs envoyés (user_id, order_id, etc.).
-
Cliquer sur un champ et l'ajouter au filtre. Recherche de logs avec conditions :
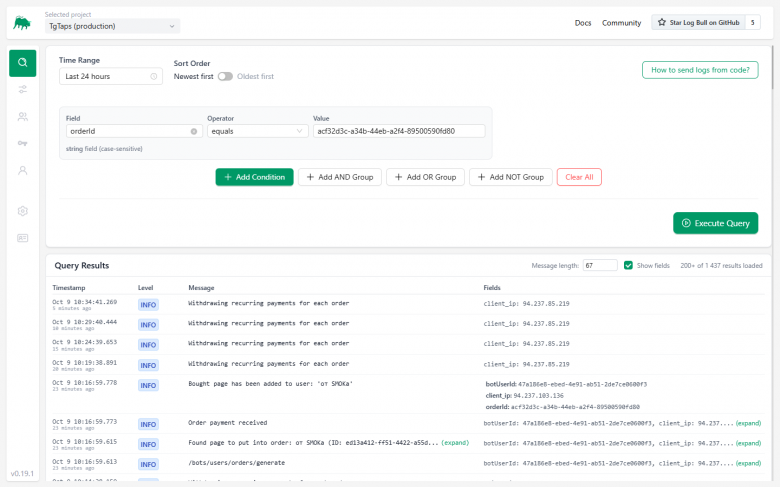
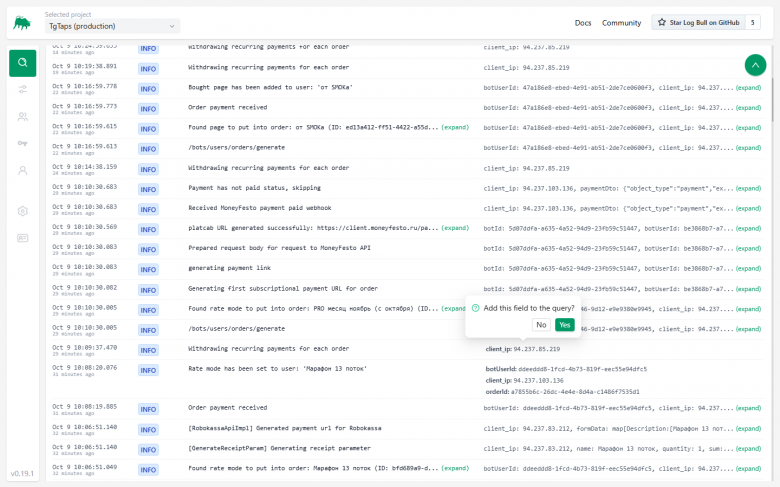
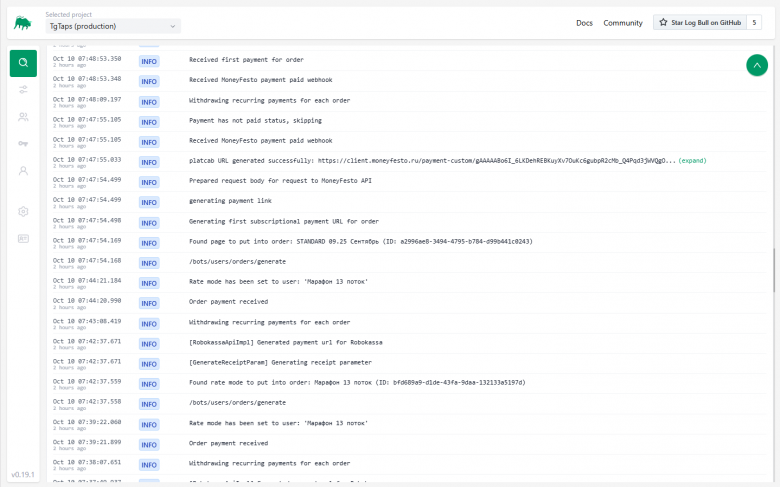
Vous pouvez également collecter des groupes de conditions (par exemple, le message inclut un certain texte, mais exclut une adresse IP de serveur spécifique).
Conclusion
J'espère que mon système de collecte de logs sera utile aux développeurs qui ne veulent pas ou ne peuvent pas (en raison de ressources limitées du projet) mettre en œuvre des solutions "lourdes" comme ELK. J'utilise déjà Log Bull dans des projets de production, et tout se passe bien. Je suis ouvert aux commentaires, aux suggestions d'amélioration et aux problèmes sur GitHub.
Vous aimerez peut-être aussi

Folks Finance dépasse le cap des 10 millions de dollars de TVL sur la blockchain Monad

Prédiction du Prix de Cardano : L'ETF de Bitwise Est Lancé Avec ADA à l'Intérieur – Wall Street Va-t-il Faire Monter ADA Ensuite ?
