

Why Traditional Software Development Life Cycle (SDLC) Fails for Voice AI and How to Build Agents Instead
Customer conversations now happen live, with expectations shaped by how humans speak, interrupt, interpret, hesitate, and change their minds. When automation fails in this environment, there is no buffer. The failure is immediate, and the customer experiences it in real time.
Voice AI systems now operate on live calls where each error directly affects customer experience. Traditional development methods often miss these issues, which only emerge during real interactions.
Many teams still design voice agents using assumptions from conventional software development. This mismatch delays iteration, raises production risks, and makes behavior harder to interpret after deployment. The challenge is rarely model capability. It is the instinct to apply deterministic logic to systems that behave unpredictably when exposed to real users.
Addressing this requires accepting uncertainty as a constant and designing development processes that learn from it rather than resist it. The Voice Agent Development Life Cycle (VADLC) offers that foundation. It reframes design, testing, deployment, and operations by treating iteration and variability as core behaviors.
Why Traditional SDLC Breaks Down in Voice AI
Traditional software development life cycles were designed for deterministic systems, where inputs yield predictable outputs. Engineers define requirements upfront, implement logic, test outcomes, and deploy with confidence. Iteration remains fast because failures are isolated, reproducible, and inexpensive to fix. Voice AI breaks these assumptions from the start.
Voice agents pursue goals, not fixed logic paths. They handle unstructured language, user interruptions, rephrasing, and incomplete inputs in real time. Every call has a cost and affects the customer. Mistakes appear during actual interactions, not in pre-deployment testing.
This slows iteration and raises costs. Every call consumes compute, telephony, and opportunity. Tuning is slower, and errors are more expensive. Treating voice agents like traditional software often produces systems that appear reliable in testing but break down when real customers introduce ambiguity.
Voice AI is not traditional software with speech added. It belongs to a different class of systems designed to function within human communication.
From Early AI Limitations to LLM-Powered Voice Agents
 Photo: LLMs enable contextual and multi-turn conversational reasoning – Shutterstock
Photo: LLMs enable contextual and multi-turn conversational reasoning – Shutterstock
Early AI systems were brittle, using rigid rules and logic trees that failed under minor phrasing changes. They couldn’t generalize beyond narrow use cases.
Large language models changed that foundation by introducing contextual understanding, multi-turn reasoning, and dynamic language generation within a unified system. Voice agents can now reason through conversations, trigger tools, and respond naturally in real time. This supports multi-turn voice automation and tool use in real time during live calls.
But this flexibility introduces risk. LLMs behave unpredictably, and identical inputs can yield different outputs. Hallucinations are not edge cases in these systems. They are expected behaviors that must be anticipated and managed. This challenges development practices based on repeatability and strict control.
Goal-Centric, Agentic Design for Voice Systems
Voice agents perform best with declarative, goal-driven design focused on outcomes like intent fulfillment, sentiment alignment, and policy compliance, rather than fixed scripts.
Since phrasing varies from call to call, systems must ensure stability at the level of meaning. A booking confirmation can be phrased differently while still fulfilling the same intent and sentiment. Systems tuned to exact words often break when users speak unpredictably.
In voice systems, generalization matters more than linguistic precision because meaning, not phrasing, determines success. Declarative goals allow agents to adapt to variation while respecting business rules and leveraging how LLMs operate.
Voice interactions also require agents to handle pauses, interruptions, and changes in direction. The VADLC treats unpredictability as a design constraint, supporting flexible behavior without rigid flows.
The Voice Agent Development Life Cycle (VADLC)
VADLC reflects how voice agents behave in the real world. It treats development as a continuous loop of learning and improvement, not a one-way pipeline.
The lifecycle includes design, build, test, user testing, deployment, analysis, and iteration. Each stage informs the next. Learning is ongoing because behavior never becomes fully stable.
Traditional SDLC optimizes for predictability. VADLC prioritizes learning in unpredictable conditions. That distinction shapes every downstream decision, from testing strategy to deployment controls. The lifecycle below captures how these stages connect in practice.
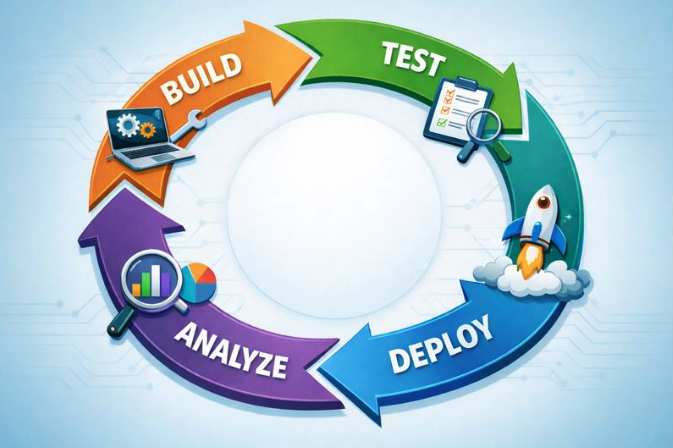 Visual 1. The VADLC illustrates the continuous feedback loop required to operate non-deterministic Voice AI systems in production.
Visual 1. The VADLC illustrates the continuous feedback loop required to operate non-deterministic Voice AI systems in production.
Testing and UAT: Validating Non-Deterministic Voice Agents
Testing voice agents requires a different mindset than testing traditional software. Multi-turn conversations and real-time interaction require validation strategies that accommodate variability rather than suppress it.
Why Traditional Testing Fails
Traditional tests rely on static assertions. Given input A, the system should produce output B. That assumption fails immediately with LLM-based agents.
Many failures become visible only across extended, multi-turn interactions. An agent may perform correctly for several turns before hallucinating, losing context, or violating policy. Research shows that LLM agent accuracy must be measured across full conversations, not isolated turns. Surveys of multi-turn evaluation methods reinforce the idea that deterministic pass-or-fail testing cannot capture real agent behavior.
Content-Level Validation Over Audio Fidelity
Audio clarity is important, but the content of the response matters more. A clear voice that delivers incorrect information still fails the user, which is why effective testing focuses on intent preservation, policy adherence, and hallucination detection.
Teams increasingly use AI-driven agent testing to validate what the agent says, not just how it sounds. In practice, Retell focuses on content-level testing, capturing meaning, detecting flow breakdowns, and identifying hallucinations that audio-focused validation often misses.
This approach aligns with how modern voice platforms validate agents, emphasizing meaning and compliance over superficial audio quality.
UAT as a Continuous Discipline
Voice conversations include nuances that structured tests miss, such as tone, pacing, and phrasing. These can trigger unexpected paths.
User acceptance testing isn’t a single phase. It’s an ongoing discipline that reveals flow failures and missed escalations through repeated evaluation. Real-world reliability comes from iteration and refinement, not a final acceptance step.
Deployment and Versioning in Customer-Facing Voice Systems
Deployments connect agents to live users, APIs, and telephony systems. Each update affects the next customer call. Strict version control over prompts, logic, and configurations is critical to maintain consistency and compliance. Even minor changes take effect immediately, leaving no room for rollout buffers.
This raises governance and monitoring needs absent in traditional software. Risk frameworks for generative AI emphasize continuous oversight rather than single-point validation.
Many voice agents begin as solo projects. Traditional infrastructure evolved for teams, but voice systems often start with one developer. Over time, they will adopt collaborative workflows, versioning, and change control. Modern platforms will support this shift by allowing coordinated updates without disrupting behavior.
Analysis, Model Evolution, and the Future of Voice AI
Voice agents produce rich behavioral data. Summaries help, but often miss deeper patterns. Effective analysis requires granular tools. Retell’s platform lets teams filter individual calls by sentiment, success, latency, cost, or issue type to identify root causes. This exposes recurring problems and helps improve logic and performance.
Latency and cost tracking reveal trade-offs that impact customer satisfaction and operational efficiency. Structured post-call analysis surfaces insights into lead quality, escalation triggers, and recurring issue trends. This helps teams refine agent behavior and measure ROI.
Dashboards and call-level tools surface systemic issues that aggregated metrics and summaries often hide. This depth of analysis depends on strong agent observability and production-grade monitoring, enabling teams to detect hallucinations, inefficient flows, and hidden operational barriers.
As models advance, systems must evolve with them. Fragile prompt chains demand constant manual updates as models and deployment conditions change. Agentic frameworks reduce maintenance overhead by separating goals from model behavior, allowing agents to improve naturally as models evolve.
Voice AI is becoming foundational to customer experience infrastructure. Legacy development methods slow progress and increase operational risk. The VADLC offers a development model aligned with how voice agents actually behave in production, emphasizing continuous learning rather than the illusion of stability.
References:
- Guan, S., Xiong, H., Wang, J., Bian, J., Zhu, B., & Lou, J.-G. (2025, March 28). Evaluating LLM-based agents for multi-turn conversations: A survey. arXiv. https://arxiv.org/abs/2503.22458
- Microsoft Azure. (2025, August 27). Agent Factory: Top 5 agent observability best practices for reliable AI. Azure Blog. [Blog]. https://azure.microsoft.com/en-us/blog/agent-factory-top-5-agent-observability-best-practices-for-reliable-ai/
- National Institute of Standards and Technology. (2024, January 24). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (NIST AI 600-1). National Institute of Standards and Technology. https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
- OpenAI. (2025, June 26). Retell AI. https://openai.com/index/retell-ai/
- Retell AI Documentation. (2025). Test overview. https://docs.retellai.com/test/test-overview
You May Also Like

XRP Buyers Defend Most Major 200-Week Price Average: Can It Be Bottom of 2026?

Expert Tags Ethereum’s ERC-8004 Mainnet Launch An “iPhone Moment”, Here’s What It Means

