

Smarter AI Training with Few-Shot Natural Language Tasks

Table of Links
Abstract and 1. Introduction
-
Background
2.1 Mixture-of-Experts
2.2 Adapters
-
Mixture-of-Adaptations
3.1 Routing Policy
3.2 Consistency regularization
3.3 Adaptation module merging and 3.4 Adaptation module sharing
3.5 Connection to Bayesian Neural Networks and Model Ensembling
-
Experiments
4.1 Experimental Setup
4.2 Key Results
4.3 Ablation Study
-
Related Work
-
Conclusions
-
Limitations
-
Acknowledgment and References
Appendix
A. Few-shot NLU Datasets B. Ablation Study C. Detailed Results on NLU Tasks D. Hyper-parameter
A Few-shot NLU Datasets
Data. In contrast to the fully supervised setting in the above experiments, we also perform fewshot experiments following the prior study (Wang et al., 2021) on six tasks including MNLI (Williams et al., 2018), RTE (Dagan et al., 2005; Bar Haim et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., 2009), QQP[1] and SST-2 (Socher et al.). The results are reported on their development set following (Zhang et al., 2021). MPQA (Wiebe et al., 2005) and Subj (Pang and Lee, 2004) are used for polarity and subjectivity detection, where we follow (Gao et al., 2021) to keep 2, 000 examples for testing. The few-shot model only has access to |K| labeled samples for any task. Following true few-shot learning setting (Perez et al., 2021; Wang et al., 2021), we do not use any additional validation set for any hyper-parameter tuning or early stopping. The performance of each model is reported after fixed number of training epochs. For a fair comparison, we use the same set of few-shot labeled instances for training as in (Wang et al., 2021). We train each model with 5 different seeds and report average performance with standard deviation across the runs. In the few-shot experiments, we follow (Wang et al., 2021) to train AdaMix via the prompt-based fine-tuning strategy. In contrast to (Wang et al., 2021), we do not use any unlabeled data.
\
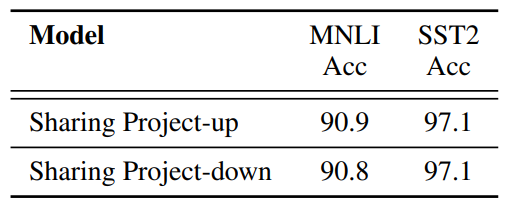
B Ablation Study
\ 
\
C Detailed Results on NLU Tasks
The results on NLU tasks are included in Table 1 and Table 13. The performance AdaMix with RoBERTa-large encoder achieves the best performance in terms of different task metrics in the GLUE benchmark. AdaMix with adapters is the
\ \ 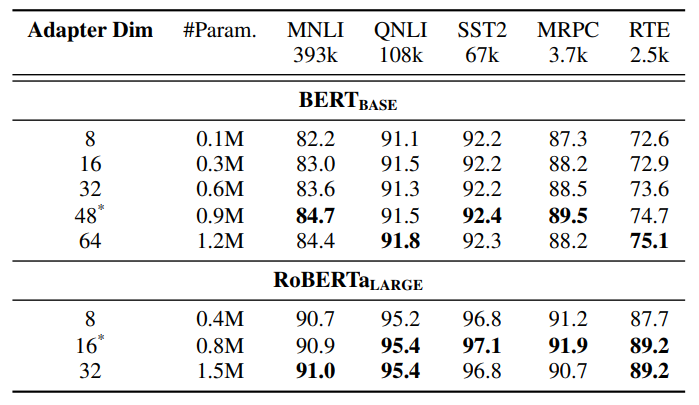
\ \ only PEFT method which outperforms full model fine-tuning on all the tasks and on average score. Additionally, the improvement brought by AdaMix is more significant with BERT-base as the encoder, demonstrating 2.2% and 1.2% improvement over the performance of full model fine-tuning and the best performing baseline UNIPELT with BERTbase. The improvement is observed to be consistent as that with RoBERTa-large on every task. The NLG results are included in Table 4 and 5.
D Hyper-parameter
Detailed hyper-parameter configuration for different tasks presented in Table 15 and Table 16.
\
:::info Authors:
(1) Yaqing Wang, Purdue University ([email protected]);
(2) Sahaj Agarwal, Microsoft ([email protected]);
(3) Subhabrata Mukherjee, Microsoft Research ([email protected]);
(4) Xiaodong Liu, Microsoft Research ([email protected]);
(5) Jing Gao, Purdue University ([email protected]);
(6) Ahmed Hassan Awadallah, Microsoft Research ([email protected]);
(7) Jianfeng Gao, Microsoft Research ([email protected]).
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[1] https://www.quora.com/q/quoradata/


Ayrıca Şunları da Beğenebilirsiniz

Stunning 96% Surge And 50% Plunge Define Volatile Market Session

Whole Health Everyday’s In-Home Chef Model Offers Alternative to Traditional Meal Delivery Services



