

技術細節:BSGAL 訓練、Swin-L 骨幹網路和動態閾值策略
連結表格
摘要和1 引言
-
相關工作
2.1. 生成式資料增強
2.2. 主動學習和資料分析
-
預備知識
-
我們的方法
4.1. 理想情境下的貢獻估計
4.2. 批次流式生成主動學習
-
實驗和5.1. 離線設定
5.2. 線上設定
-
結論、更廣泛影響和參考文獻
\
A. 實現細節
B. 更多消融實驗
C. 討論
D. 視覺化
A. 實現細節
A.1. 資料集
我們選擇LVIS (Gupta等人,2019)作為我們實驗的資料集。LVIS是一個大規模實例分割資料集,包含約160,000張圖像,超過200萬個高品質實例分割標註,涵蓋1203個真實世界類別。該資料集根據它們在圖像中出現的頻率進一步分為三類:稀有、常見和頻繁。標記為「稀有」的實例出現在1-10張圖像中,「常見」實例出現在11-100張圖像中,而「頻繁」實例出現在超過100張圖像中。整個資料集呈現長尾分佈,與真實世界的資料分佈非常相似,並廣泛應用於多種設定,包括少樣本分割(Liu等人,2023)和開放世界分割(Wang等人,2022; Zhu等人,2023)。因此,我們認為選擇LVIS能更好地反映模型在真實世界場景中的表現。我們使用官方LVIS資料集分割,訓練集約有100,000張圖像,驗證集有20,000張圖像。
A.2. 資料生成
我們的資料生成和標註過程與Zhao等人(2023)一致,在此簡要介紹。我們首先使用StableDiffusion V1.5 (Rombach等人,2022a) (SD)作為生成模型。對於LVIS (Gupta等人,2019)中的1203個類別,我們為每個類別生成1000張圖像,圖像解析度為512 × 512。生成的提示模板為"a photo of a single {CATEGORY NAME}"。我們分別使用U2Net (Qin等人,2020)、SelfReformer (Yun和Lin,2022)、UFO (Su等人,2023)和CLIPseg (Luddecke和Ecker,2022)來標註原始生成圖像,並選擇CLIP分數最高的遮罩作為最終標註。為確保資料品質,CLIP分數低於0.21的圖像被過濾為低品質圖像。在訓練過程中,我們還採用Zhao等人(2023)提供的實例貼上策略進行資料增強。對於每個實例,我們隨機調整其大小以匹配其類別在訓練集中的分佈。每張圖像貼上的最大實例數設為20。
\ 此外,為了進一步擴展生成資料的多樣性並使我們的研究更加普遍,我們還使用了其他生成模型,包括DeepFloyd-IF (Shonenkov等人,2023) (IF)和Perfusion (Tewel等人,2023) (PER),每個模型每個類別500張圖像。對於IF,我們使用作者提供的預訓練模型,生成的圖像是Stage II的輸出,解析度為256×256。對於PER,我們使用的基礎模型是StableDiffusion V1.5。對於每個類別,我們使用從訓練集裁剪的圖像對模型進行微調,微調步驟為400步。我們使用微調後的模型生成圖像。
\ 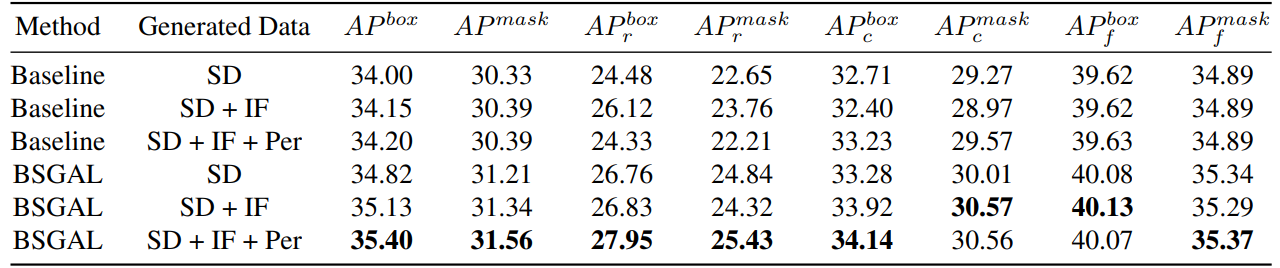
\ 我們還探索了使用不同生成資料對模型性能的影響(見表7)。我們可以看到,基於原始StableDiffusion V1.5,使用其他生成模型可以帶來一些性能提升,但這種提升並不明顯。具體來說,對於特定頻率類別,我們發現IF對稀有類別有更顯著的改進,而PER對常見類別有更顯著的改進。這可能是因為IF資料更加多樣化,而PER資料與訓練集的分佈更加一致。考慮到整體性能已經提升到一定程度,我們最終採用SD + IF + PER的生成資料進行後續實驗。
A.3. 模型訓練
遵循Zhao等人(2023),我們使用CenterNet2 (Zhou等人,2021)作為我們的分割模型,以ResNet-50 (He等人,2016)或Swin-L (Liu等人,2022)作為骨幹網絡。對於ResNet-50,最大訓練迭代次數設為90,000,模型初始化權重首先在ImageNet-22k上預訓練,然後在LVIS (Gupta等人,2019)上微調,正如Zhao
\ 
\ 等人(2023)所做的。我們在訓練期間使用4個Nvidia 4090 GPU,批次大小為16。至於Swin-L,最大訓練迭代次數設為180,000,模型初始化權重在ImageNet-22k上預訓練,因為我們的早期實驗表明,與在LVIS上訓練的權重相比,這種初始化可以帶來輕微的改進。我們使用4個Nvidia A100 GPU進行訓練,批次大小為16。此外,由於Swin-L參數數量龐大,保存梯度所佔用的額外記憶體很大,所以我們實際上使用演算法2中的演算法。
\ 其他未指定的參數也遵循與X-Paste (Zhao等人,2023)相同的設定,例如AdamW (Loshchilov和Hutter,2017)優化器,初始學習率為1e−4。
A.4. 資料量
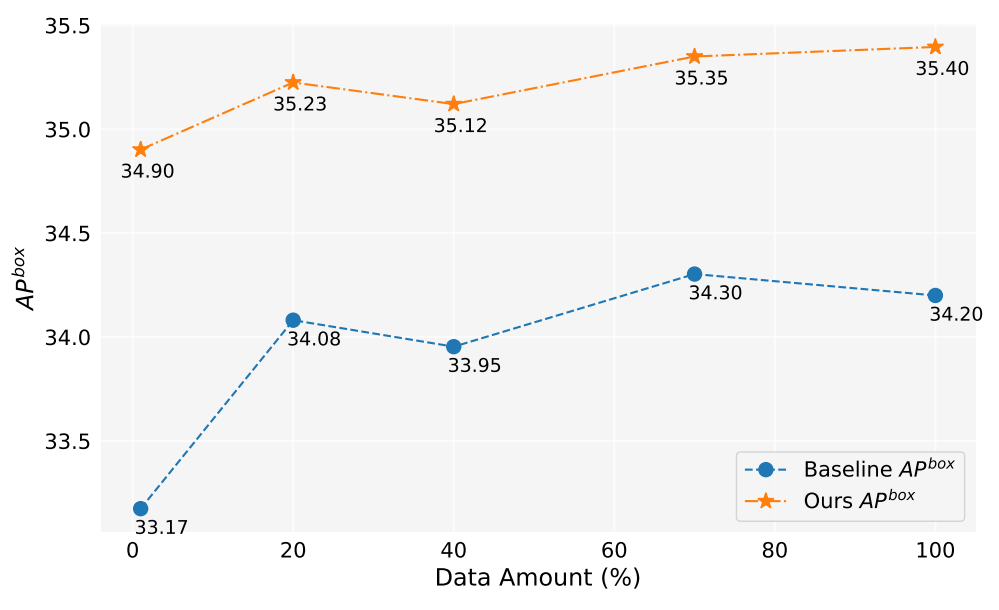
在這項工作中,我們已生成超過200萬張圖像。圖5顯示了使用不同數量生成資料(1%,10%,40%,70%,100%)時的模型性能。總體而言,隨著生成資料量的增加,模型的性能也有所提升,但也存在一些波動。我們的方法始終優於基準線,這證明了我們方法的有效性和穩健性。
A.5. 貢獻估計
\ 因此,我們本質上計算的是餘弦相似度。然後我們進行了實驗比較,如表8所示,
\ 
\ 
\ 我們可以看到,如果我們對梯度進行歸一化,我們的方法會有一定的改進。此外,由於我們需要保持兩個不同的閾值,很難確保接受率的一致性。因此,我們採用動態閾值策略,預設一個接受率,維護一個隊列來保存前一次迭代的貢獻,然後根據隊列動態調整閾值,使接受率保持在預設的接受率。
A.6. 玩具實驗
以下是在CIFAR-10上實施的具體實驗設定:我們採用簡單的ResNet18作為基準模型,並進行了200個epoch的訓練,在原始訓練集上訓練後的準確率為93.02%。學習率設為0.1,使用SGD優化器。動量為0.9,權重衰減為5e-4。我們使用餘弦退火學習率調度器。構建的噪聲圖像如圖6所示。隨著噪聲級別的升高,圖像質量下降。值得注意的是,當噪聲級別達到200時,圖像變得非常難以識別。對於表1,我們使用Split1作為R,而G由'Split2 + Noise40'、'Split3 + Noise100'、'Split4 + Noise200'組成,
A.7. 僅前向傳播一次的簡化
\
:::info 作者:
(1) 朱慕之,來自中國浙江大學,貢獻相同;
(2) 范成祥,來自中國浙江大學,貢獻相同;
(3) 陳浩,中國浙江大學 ([email protected]);
(4) 劉洋,中國浙江大學;
(5) 毛偉安,中國浙江大學和澳大利亞阿德萊德大學;
(6) 徐曉剛,中國浙江大學;
(7) 沈春華,中國浙江大學 ([email protected])。
:::
:::info 本論文可在arxiv上獲取,遵循CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International)許可證。
:::
\
您可能也會喜歡

【CNEWS】打詐?「內政部鎖小紅書」館長嗆:帶種再封TikTok、抖音 歷史哥曝「他貼文」看出目的

「老人」梅西仍能為 MLS 冠軍國際邁阿密隊創造魔法
