

開放集語義提取:Grounded-SAM、CLIP 和 DINOv2 流程
連結表
摘要和1 引言
-
相關工作
2.1. 視覺與語言導航
2.2. 語義場景理解和實例分割
2.3. 3D場景重建
-
方法論
3.1. 數據收集
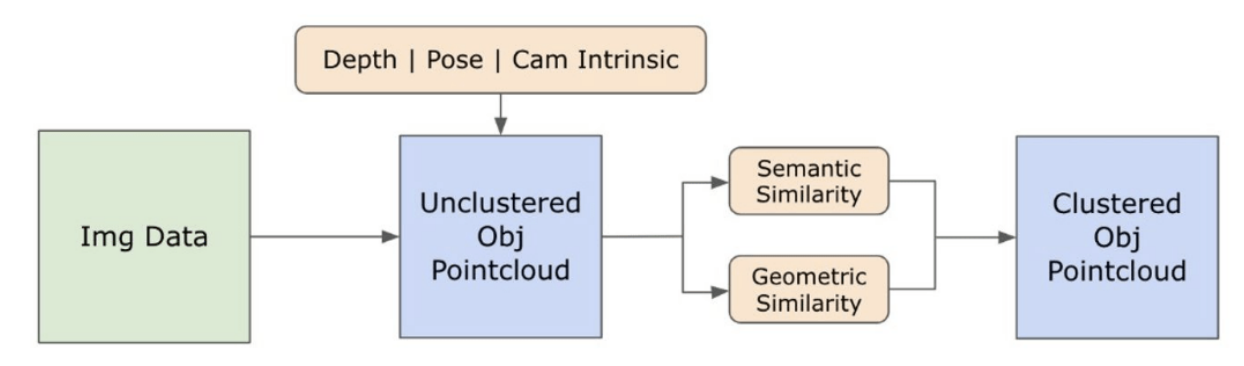
3.2. 從圖像中獲取開放集語義信息
3.3. 創建開放集3D表示
3.4. 語言引導導航
-
實驗
4.1. 定量評估
4.2. 定性結果
-
結論和未來工作、披露聲明和參考文獻
3.2. 從圖像中獲取開放集語義信息
\ 3.2.1. 開放集語義和實例遮罩檢測
\ 最近發布的Segment Anything模型(SAM)[21]因其尖端的分割能力而在研究人員和工業實踐者中獲得了顯著的歡迎。然而,SAM傾向於為同一物體產生過多的分割遮罩。為解決這個問題,我們採用了Grounded-SAM[32]模型作為我們的方法。這個過程涉及在三個階段生成一組遮罩,如圖2所示。首先,使用Recognizing Anything模型(RAM)[33]創建一組文本標籤。隨後,使用Grounding DINO模型[25]創建與這些標籤相對應的邊界框。然後將圖像和邊界框輸入到SAM中,為圖像中看到的物體生成與類別無關的分割遮罩。我們在下面提供了這種方法的詳細解釋,通過整合來自RAM和Grounding-DINO的語義見解,有效地緩解了過度分割的問題。
\ RAM模型[33]處理輸入的RGB圖像,為圖像中檢測到的物體產生語義標籤。它是一個強大的圖像標記基礎模型,展示了在準確識別各種常見類別方面的卓越零樣本能力。這個模型的輸出將每個輸入圖像與描述圖像中物體類別的一組標籤相關聯。處理過程首先訪問輸入圖像並將其轉換為RGB色彩空間,然後調整大小以適應模型的輸入要求,最後將其轉換為張量,使其與模型的分析兼容。接著,RAM模型生成描述圖像中各種物體或特徵的標籤或標記。我們採用過濾過程來精煉生成的標籤,這涉及從這些標籤中移除不需要的類別。具體來說,我們丟棄了諸如"牆"、"地板"、"天花板"和"辦公室"等不相關的標記,以及其他被認為對研究背景不必要的預定義類別。此外,這個階段允許用RAM模型最初未檢測到的任何必要類別來增強標籤集。最後,所有相關信息被匯總成一個結構化格式。具體來說,每個圖像都被編入img_dict字典中,該字典記錄了圖像的路徑以及生成的標籤集,從而確保了一個可訪問的數據庫,用於後續分析。
\ 在用生成的標籤標記輸入圖像之後,工作流程通過調用Grounding DINO模型[25]繼續進行。這個模型專門將文本短語定位到圖像中的特定區域,有效地用邊界框描繪目標物體。這個過程識別並在空間上定位圖像中的物體,為更細緻的分析奠定了基礎。在通過邊界框識別和定位物體之後,我們使用Segment Anything Model(SAM)[21]。SAM模型的主要功能是為這些邊界框內的物體生成分割遮罩。通過這樣做,SAM隔離了單個物體,通過有效地將物體與其背景和圖像中的其他物體分離,實現了更詳細和物體特定的分析。
\ 在這一點上,物體的實例已被識別、定位和隔離。每個物體都被識別出各種細節,包括邊界框坐標、物體的描述性術語、以logits表示的物體存在的可能性或置信度分數,以及分割遮罩。此外,每個物體都與CLIP和DINOv2嵌入特徵相關聯,這些特徵的詳細信息將在下一小節中闡述。
\ 3.2.2. 語義嵌入提取
\ 為了提高我們對圖像中已分割和遮罩的物體實例的語義方面的理解,我們使用兩個模型,CLIP[9]和DINOv2[10],從每個物體的裁剪圖像中獲取特徵表示。專門用CLIP訓練的模型能夠實現對圖像的強大語義理解,但無法辨別這些圖像中的深度和複雜細節。另一方面,DINOv2在深度感知方面表現出色,並且擅長識別跨圖像的細微像素級關係。作為一個自監督的Vision Transformer,DINOv2可以在不依賴註釋數據的情況下提取細微的特徵細節,使其特別有效地識別圖像中的空間關係和層次結構。例如,雖然CLIP模型可能難以區分兩把不同顏色的椅子,如紅色和綠色,但DINOv2的能力允許清晰地做出這種區分。總結來說,這些模型捕捉了物體的語義和視覺特徵,這些特徵後來用於3D空間中的相似性比較。
\ 
\ 我們為使用DINOv2模型處理圖像實施了一組預處理步驟。這些步驟包括調整大小、中心裁剪、將圖像轉換為張量,以及標準化由邊界框描繪的裁剪圖像。然後將處理後的圖像與RAM模型識別的標籤一起輸入到DINOv2模型中,以生成DINOv2嵌入特徵。另一方面,在處理CLIP模型時,預處理步驟涉及將裁剪的圖像轉換為與CLIP兼容的張量格式,然後計算嵌入特徵。這些嵌入至關重要,因為它們封裝了物體的視覺和語義屬性,這對於全面理解場景中的物體至關重要。這些嵌入基於它們的L2範數進行標準化,這將特徵向量調整為標準化的單位長度。這個標準化步驟使不同圖像之間的比較保持一致和公平。
\ 在這個階段的實施階段,我們遍歷數據中的每個圖像並執行以下程序:
\ (1) 使用Grounding DINO模型提供的邊界框坐標將圖像裁剪到感興趣區域,隔離物體以進行詳細分析。
\ (2) 為裁剪的圖像生成DINOv2和CLIP嵌入。
\ (3) 最後,將嵌入與前一節的遮罩一起存儲回去。
\ 完成這些步驟後,我們現在擁有每個物體的詳細特徵表示,豐富了我們的數據集,以供進一步分析和應用。
\
:::info 作者:
(1) Laksh Nanwani,印度海德拉巴國際信息技術學院;此作者對本工作做出了同等貢獻;
(2) Kumaraditya Gupta,印度海德拉巴國際信息技術學院;
(3) Aditya Mathur,印度海德拉巴國際信息技術學院;此作者對本工作做出了同等貢獻;
(4) Swayam Agrawal,印度海德拉巴國際信息技術學院;
(5) A.H. Abdul Hafez,土耳其加濟安泰普薩欣貝伊哈桑卡利永庫大學;
(6) K. Madhava Krishna,印度海德拉巴國際信息技術學院。
:::
:::info 本論文可在arxiv上獲取,根據CC by-SA 4.0 Deed(署名-相同方式共享4.0國際)許可證。
:::
\
您可能也會喜歡

為何有些人仍搬遷至「藍區」長灘島

BRBP奪冠!高流樂團興奮波大賽出爐 將挑戰《下酒祭》與跨年舞台
